
[모두의 인공지능 with 파이썬] 넷째마당 딥러닝 프로그래밍 시작하기 2 – 숫자 인식 인공지능 만들기
숫자 인식 인공지능 만들기 : https://www.youtube.com/watch?v=RG-wilw9wBg&list=PLa9dKeCAyr7iXpGqNHKXmeqB6LLo7ieS9&index=30
UNIT 16 숫자 인식 인공지능 만들기 (개발환경 만들기)
숫자를 알아맞히는 인공 지능 만들기 – 이미지 인식 딥러닝
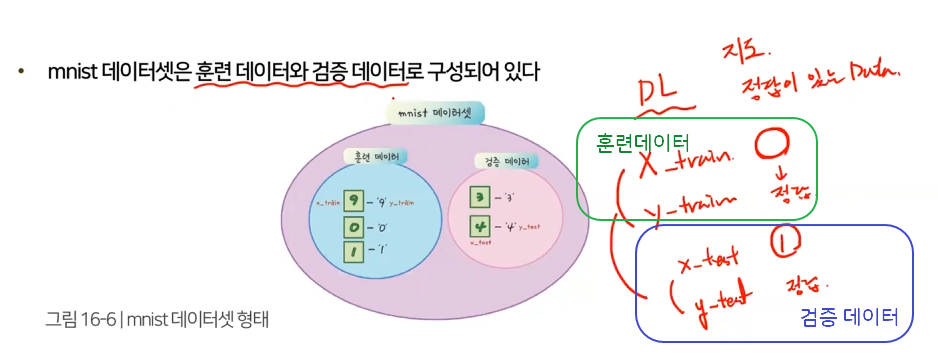
MNIST 데이터셋 : 숫자 인식 인공지능 만들 때 가장 많이 사용하는 데이터 셋. 70,000개 손글씨가 있음
숫자는 0 ~9 까지 총 10개로 구성되며, 각 숫자 이미지마다 레이블이 달려있음.
개발 환경 만들기
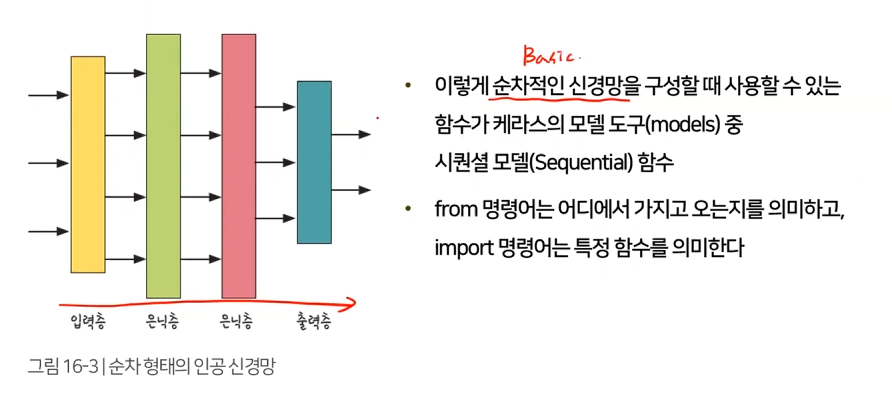
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
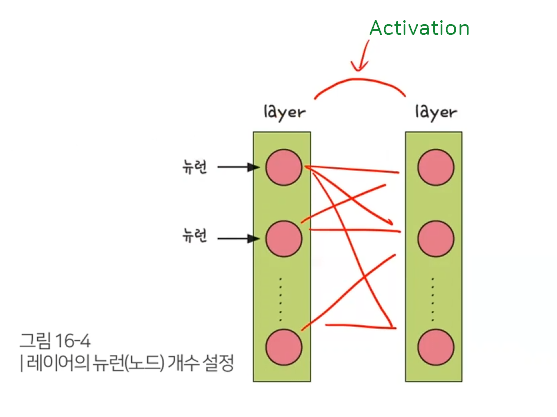
레이어 도구(layers) 중 Dense(전결합층 – 입력층, 은닉층, 출력층과 같은 층이 바로 앞 층과 서로 연결되어 있는 것. 뉴런 개수 설정)와 Activation(활성화 함수) 도구를 불러오는 명령어
from tensorflow.keras.utils import to_categorical
유틸 도구(utils) 중 to_categorical(원-핫 인코딩 기법 사용, 구현 가능) 함수를 불러오는 명령어
우리갈 만들 모델은 0~9사이 숫자 이미지 구별하는 다중분류 – 원 핫 인코딩 사용함
from tensorflow.keras.datasets import mnist
케라스 사용하여 딥러닝 모델 개발을 연습할 수 있는 데이터는 데이터 셋 도구(datasets)에 있으며, mnist 데이터셋을 불러오는 명령어
import numpy as np
넘파이라는 수학 계산 라이브러리. as 명령어로 함수 이름 변경
import matplotlib.pyplot as plt
맷플로립이라는 그래프 라이브러리 사용. 결과 시각화
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Activation from tensorflow.keras.utils import to_categorical from tensorflow.keras.datasets import mnist import numpy as np import matplotlib.pyplot as plt
데이터셋 불러오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape" , x_train.shape)
print("y_train shape" , y_train.shape)
print("x_test shape" , x_test.shape)
print("y_test shape" , y_test.shape)
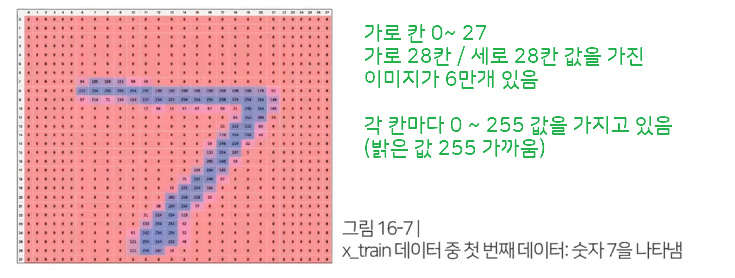
# x_train shape (60000, 28, 28)
y_train shape (60000,)
x_test shape (10000, 28, 28)
y_test shape (10000,)mnist.load_data() : mnist 데이터셋에서 데이터 불러오라는 명령어
mnist 데이터는 이미 4부분(x_train, y_train, x_test, y_test) 으로 나눠져 있는데, 모두 넘파이 라이브러리를 사용하여 만든 값으로 훈련 데이터와 검증 데이터로 구성되어 있음
x_train shape
y_train shape
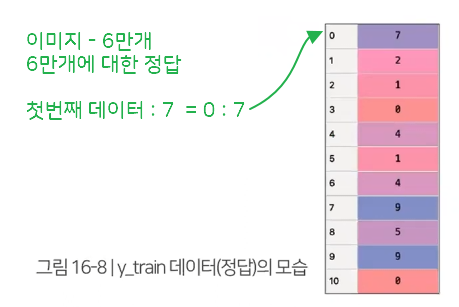
x_train 와 x_test 데이터의 차이는 갯수 차이만 있음
mnist 데이터셋에서 X의 형태 바꾸기
딥러닝 모델 만들 때 가장 중요하건 = 데이터 전처리 과정(내가 만들고자 하는 딥러닝 모델에 맞게끔 데이터 변형)
기존 28 x 28 데이터를 -> 1 x 784로 변경
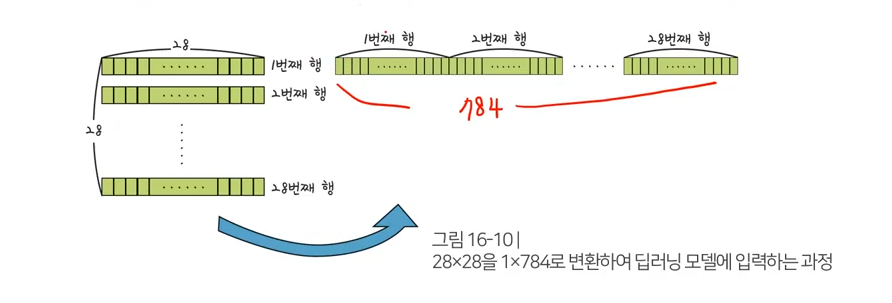
X_train = x_train.reshape(60000, 784) # shape를 28x28를 1x784로 데이터형태 바꿈
X_test = x_test.reshape(10000, 784) # reshape는 넘파이 명령어임
X_train = X_train.astype('float32') # 0 ~ 255값은 편차가 커서 데이터를 0 ~ 1 사이 값으로 바꿔 성능 업.
X_test = X_test.astype('float32') # 정규화 : 나누기 할껀데 소수점으로 떨어지니 자료형을 바꿔줌
X_train /= 255 # (정수형 -> 실수형) 0 ~ 1 사이 값으로 하려고 나누기 255를 해줌
X_test /= 255
print("X Training matrix shape " , X_train.shape) # X Training matrix shape (60000, 784)
print("X Testing matrix shape " , X_test.shape) # X Testing matrix shape (10000, 784)mnist 데이터셋에서 Y의 형태 바꾸기
우리가 만드는 인공지능 목표는 숫자의 특정보다 구분을 잘 하는것 = 레이블(정답)을 더 잘 구분할 수 있는 방법이 필요
수치형 데이터를 범주형 데이터로 변환 필요 ex> 0이라는 숫자는 10개의 숫자 중 1번째 숫자야
예측이 아닌 분류 문제에서 대부분 정답 레이블을 첫 번째, 두 번째, 세 번째와 같이 순서로 나타내도록 데이터의 형태를 바꿈 – 이때 원-핫 인코딩(one-hot inconding) 사용
Y_train = to_categorical(y_train, 10) # Y_train 데이터를 원-핫 인코딩. 구분 값이 10개라 10 지정
Y_test = to_categorical(y_test, 10) # to_categorical 함수는 수치형 -> 범주형 데이터로 만듦
print('Y Training matrix shape' , Y_train.shape) # Y Training matrix shape (60000, 10)
print('Y Testing matrix shape' , Y_test.shape) # Y Testing matrix shape (10000, 10)
- 기존 (60000,)와 출력값 달라짐 1개가 아니라 10개 됨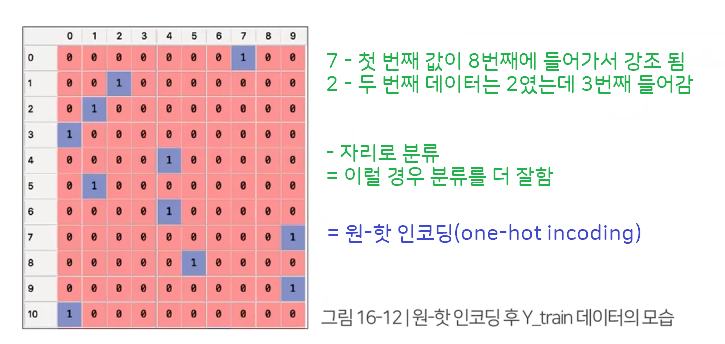
인공지능 모델 설계하기
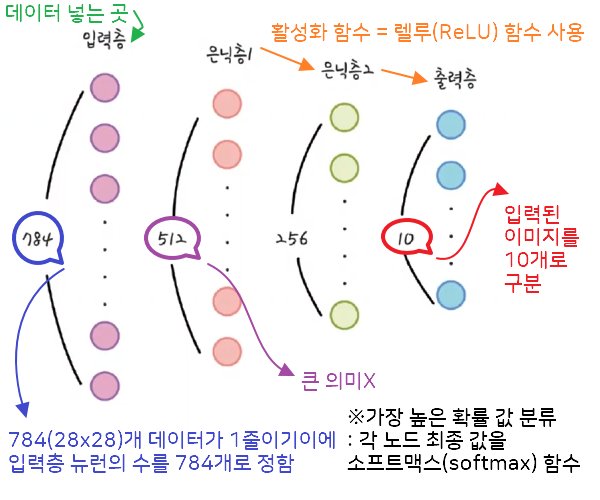
model = Sequential() # 모델을 시퀀셜 방식으로 개발 (케라스-시퀀셜 모델)
model.add(Dense(512, input_shape = (784, ))) # 모델에 층 추가. 층이 어떤 형태인지 Dense 함수 사용
# 512 = 은닉층 노드수 / input_shape = 입력하는 데이터 형태
model.add(Activation('relu')) # 다음 층으로 값 전달시 사용할 활성화 함수 - 렐루함수
model.add(Dense(256)) # 값만 추가 - 입력받는 노드 설정X = 케라스가 해줌
model.add(Activation('relu'))
model.add(Dense(10)) # 마지막 출력 10개 받기(0 ~ 9)
model.add(Activation('softmax')) # 값 총합 1로 바꿔주는 소프트맥스 함수 사용
model.summary() # 어떤 모델로 구성되어 있는지 살펴보기
모델 학습 시키기
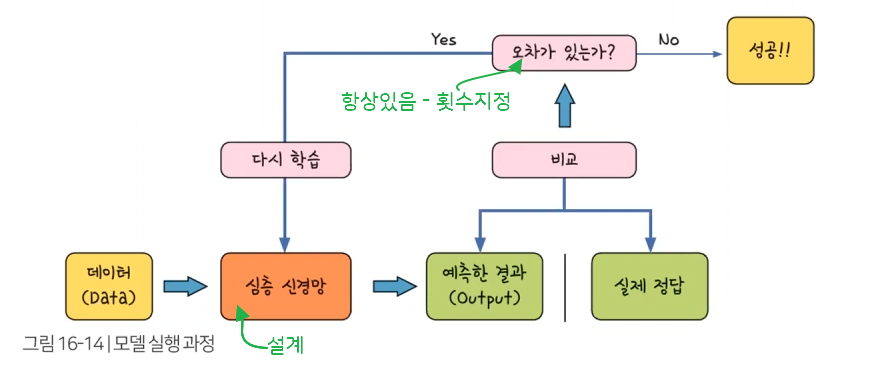
신경망 잘 학습시키려면 학습한 신경망이 분류한 값과 실제 값의 오차부터 계산
그 오차를 줄이기 위해 경사 하강법을 사용함
model.compile(loss='categorical_crossentropy', optimizer = 'adam', metrics=['accuracy']) model.fit(X_train, Y_train, batch_size=128, epochs=10, verbose=1)

케라스는 심층 신경망의 학습하는 방법을 정하는 명령어인 compile 함수 제공 – 설계
- compile 함수 사용 규칙1: 오차값 계산하는 방법 지시 – 여기선 10개 중 하나 분류하는 다중 분류라 categorical_crossentropy 사용
- compile 함수 사용 규칙2 : 오차 줄이는 방법 지시 – optimizer로 오차 줄이기 中 adam 방법 사용
- compile 함수 사용 규칙3: 학습 결과 어떻게 확인할지 지시 – 정확도(accuracy)- 실제 6만개 데이터의 예측 결과와 실제 값을 비교해 본 후 정답 비율을 알려줌
케라스는 학습 시키기 위해 fit 함수 제공 – 동작
- fit 함수 사용 규칙 1: 입력할 데이터 정하기 – 학습 X_trian, 정답 Y_train
- fit 함수 사용 규칙 2: 배치 사이즈 정하기 – 인공모델이 한 번에 학습하는 데이터 수 – 한번에 128개 데이터 학습
- fit 함수 사용 규칙 3: 에포크 정하기 – 모든 데이터를 1번 학습하는 것을 의미 – 여기선 10번 반복
- fit 함수 사용 규칙 4: verbose 정하기 – fit 함수 결과값을 출력하는 방법 – 0, 1, 2 중 하나로 결
verbose – 케라스 결과 값 출력 방법
- verbose 0 : 아무런 표시 X
- verbose 1 : 에포크별 진행 사항을 알려줌
- verbose 2 : 에포크별 학습 결과를 알려줌
모델 학습 결과 확인하기
인공지능이 잘 구분한 그림과 잘 구분하지 않은 그림 살펴보기
predicted_classes = np.argmax(model.predict(X_test), axis = 1) correct_indices = np.nonzero(predicted_classes == y_test)[0] incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
값 예측 – np.argmax(model.predict(X_test), axis = 1)
인공지능 모델인 model에서 결과 예측하는 함수인 predict 함수 제공. 여기에 검증 데이터 (X_test)입력
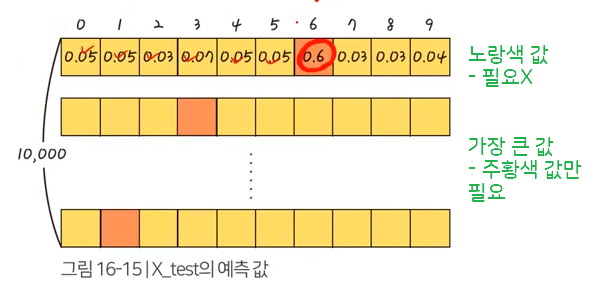
소프트 맥스 함수 사용 – 1에 가장 가까운 높은 값 찾아짐
axis
- np.argmax 함수 사용 시 – 열 중에서 가장 큰 것을 고를지, 행 중에서 가장 큰 것을 고를지 알려줘야 함
- axis = 0 : 세로(열) 중 가장 큰 값
- asix = 1 : 가로(행) 중 가장 큰 값
정확하게 예측한 값과 부정하게 예측한 값 구분 – np.nonzero(predicted_classes == y_test)[0] / incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
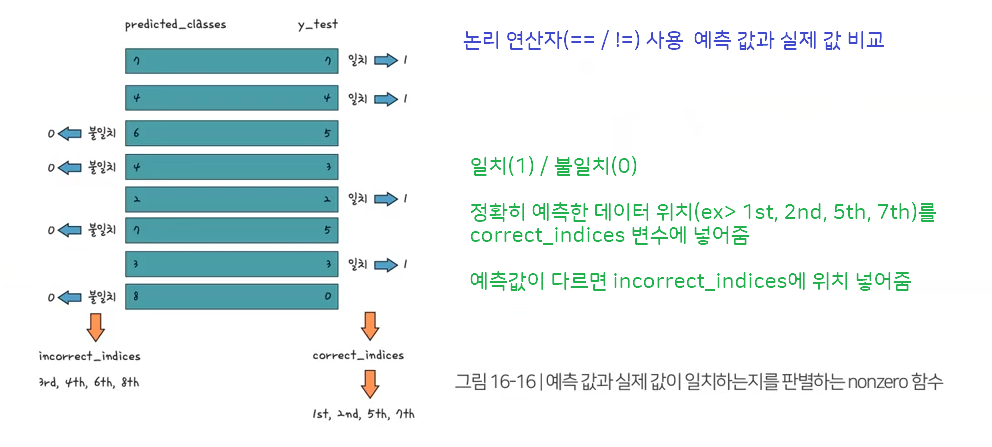
잘 예측한 데이터 살펴보기
plt.figure() # 그림 그리겠다는 명령어
for i in range(9):
plt.subplot(3, 3, i+1) # subplot함수 : 그림 위치 정해주는 함수 - 가로 개수 / 세로 개수 / 인자 순서
correct = correct_indices[i] # 위 correct_indices 배열에서 앞에서 9번째까지 가져옴
plt.imshow(X_test[correct].reshape(28,28), cmap='gray')
# imshow함수 : 어떤 이미지 보여줄지 / 처음에 1줄 해줬기에 다시 28x28로 reshape
plt.title("Predicted {}, Class{}".format(predicted_classes[correct], y_test[correct]))
# 타이틀 넣어주기 - 예측 값과 실제 값 넣어주기
plt.tight_layout() # 화면에 그림 보여주기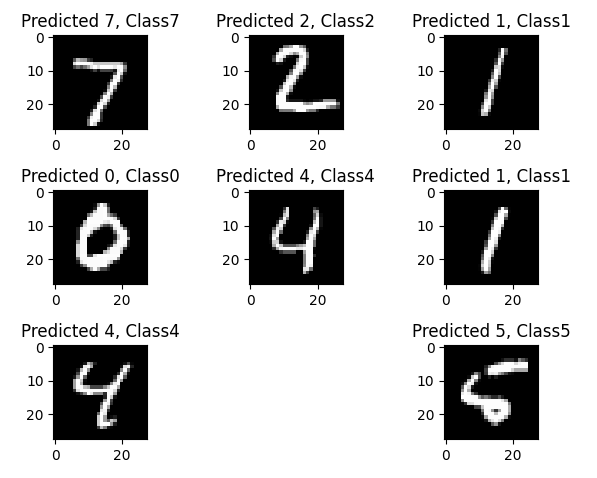
잘 예측하지 못한 데이터 살펴보기
변수만 변경
plt.figure()
for i in range(9):
plt.subplot(3, 3, i+1)
incorrect = incorrect_indices[i]
plt.imshow(X_test[incorrect].reshape(28,28), cmap='gray')
plt.title("Predicted {}, Class{}".format(predicted_classes[incorrect], y_test[incorrect]))
plt.tight_layout()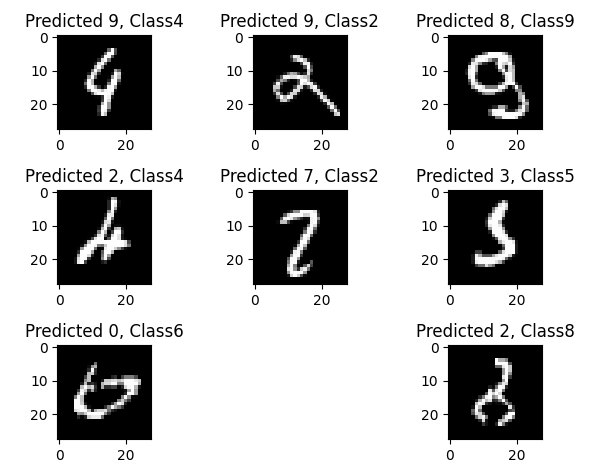
[모두의 인공지능 with 파이썬] 첫째마당. 인공지능 개념 이해하기
[모두의 인공지능 with 파이썬] 둘째마당. 딥러닝 이해하기
[모두의 인공지능 with 파이썬] 셋째마당 인공지능 개발을 위한 파이썬 첫걸음
[모두의 인공지능 with 파이썬] 넷째마당 딥러닝 프로그래밍 시작하기 1
[모두의 인공지능 with 파이썬] 넷째마당 딥러닝 프로그래밍 시작하기 2 – 숫자 인식 인공지능 만들기