

Python

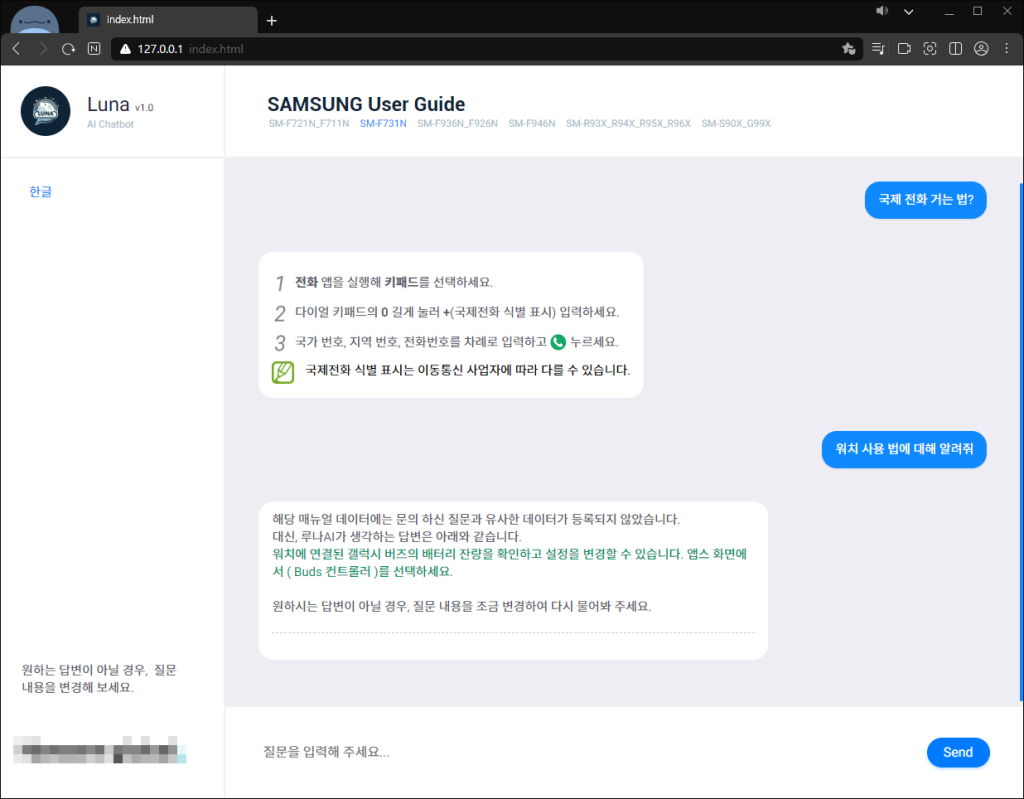
project Luna 는 매뉴얼에 대한 질문을 하면 내가 가진 매뉴얼에 대한 데이터를 기반으로 답을 해주는 AI이다. 학습은 따로 json으로 데이터를 만들어서 시켰고, 답변은 1차로 HTML에 동일한 질문 유형이 있으면 HTML 형식(이미지와 css화 된)으로 답해주며 없으면 자신이 학습한 대로 텍스트로 대답하는 콘셉트를 가지고 만들어 졌다.
아래는 내가 아무것도 모르는 상태에서 AI 개발을 위해 설치 했던 프로그램 등을 정리해 두었다.
마지막 프로젝트 정리 내용은 : #project-Luna-1차-마무리 여기에…
Hugging Face사의 Transformers 라이브러리 + Pytorch 프레임워크 사용
D:\Python\python311\python -m venv vLuna
현 시점 최신 버전이 3.12이나 pytorch 문제로 3.11 버전 선택
이유는 [python/error] pytorch설치 에러- No matching distribution found for torch 여기에…
python.exe -m pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
transformers 보다 pytorch를 꼭 먼저 설치 해야 함
이유는 [python/error] transformers 설치 에러 – error: subprocess-exited-with-error 이래서 ㅠㅡㅠ
pip install transformers
pip install pandas
엑셀 파일 읽고 쓰는 용도
pip install openpyxl
pip install -U scikit-learn
pip install Django==4.2.7 django-admin startproject back . pip install mysqlclient pip install django-cors-headers # DB + setting django-admin startproject back . python manage.py startapp web python manage.py startapp training python manage.py makemigrations python manage.py migrate python manage.py runserver python manage.py createsuperuser
pip install beautifulsoup4
pip install transformers # 문맥 고려용 DistilBERT 쓰기 위해서 pip install soynlp # 한국어 자연어 처리 용 pip install soyspacing # 한국어 띄어쓰기 용 pip install gensim # 자연어처리 - 데이터셋 pip install nltk # 영어 자연어 처리 용 python -m nltk.downloader omw-1.4
pip install konlpy
konlpy 는 선행 설치가 많았음. 그래서 관련 내용은 [설치/패키지] 파이썬 – konlpy (한국어 NLP) 한국어 정보 처리 여기 따로 정리 하였다.
일단 1차로 HTML에서는 꽤 높은 정답 확률을 가졌고, 자신이 학습한 데이터 대답 확률은 거의 바보일 정도인 결과를 보여주었지만, 학습시킨 기간이 며칠 되지 않았기에 앞으로 남은 건 학습 데이터를 모아서 학습시키는 것만 남은 상태에서 일단 2062개 데이터로 1차 개발 마무리를 지었다.
처음 해보는 AI라 중간에 몇 번의 변경이 있었지만 결국은 질문에 대해 가장 유사한 질문을 찾는 CNN 기반에 Word2Vec를 보충해 주는 분류 타입으로 마무리가 되었다. 전처리에는 soynlp, konlpy, soyspacing, mecab 등을 사용하였다.
질문에 대한 답이 없으면 아직 데이터 학습을 거의 시키지 않아서 엉뚱한 답변을 하지만… 만약 보충 하게 된다면, 데이터를 추가하고 학습을 더 시킨다면 조금 더 정확해지지 않을까…
추후 이어서 하고 싶으면 데이터 추출은 세팅해 놓았으니, 엑셀에 많은 데이터를 추가해서 학습 명령어를 눌러지면 되지만… 아마도 이 프로젝트로 돌아올 일은 없을 듯하다. 사실 1차 마무리라고 한 건 조금의 미련이 남아서 그런 걸지도 모르지만…
Pytorch : https://pytorch.org/
Transformers : https://huggingface.co/docs/transformers/v4.39.0/ko/index
Soynlp: https://datascienceschool.net/03%20machine%20learning/03.01.04%20soynlp.html
soyspacing : https://github.com/lovit/soyspacing
gensim : https://radimrehurek.com/gensim/
nltk : https://www.nltk.org/
konlpy : https://konlpy.org/ko/latest/