

Python

전염병 예측 인공지능 만들기 : https://www.youtube.com/watch?v=IUnM5D11fso&list=PLa9dKeCAyr7iXpGqNHKXmeqB6LLo7ieS9&index=38
데이터 잘 불러오고 / 잘 처리해서 – 인공지능에 집에 넣기
인공지능 사용하여 전염병 발생할 수 있는 곳 예측. 발병률 예측.
이번엔 3일 전 확진자 수 토대로 다음날 확진자 수 예측하는 인공지능 만들기
연속된 데이터 형태에서 그 패턴을 찾아내는 순환 신경망(RNN) 방식
from keras.models import Sequential # 시퀀셜 모델 불러오기 from keras.layers import SimpleRNN, Dense # 순한신경망(RNN) 기법에는 LSTM, GRU등 기법이 있는데, SimpleRNN 가장 기본적인 순환신경망 모습 # Dense: 뉴런수 from sklearn.preprocessing import MinMaxScaler # 데이터 정규화 : MinMaxScaler - 데이터 전처리(인공지능 모델에 적합하게 만들기) from sklearn.metrics import mean_squared_error # 결과 계산 정확도 계산 : mean_squared_error - 실제 값과 예측 값 차이를 사용하여 오류를 구분하는 역할 # 연속된 값 예측하는 회귀 문제로 오차 계산 법이 분류와 다름 from sklearn.model_selection import train_test_split # 훈련 데이터와 검증 데이터로 나누는 명령어 / 나누는 이유는 인공지능 성능 측정 위함 import math import numpy as np import matplotlib.pyplot as plt from pandas import read_csv # pandas는 파이썬에서 데이터 처리할 때 유용
!git clone https://github.com/yhlee1627/deeplearning.git # 데이터 불러오기
dataframe = read_csv('/content/deeplearning/corona_daily.csv', usecols=[3], engine='python', skipfooter=3)
# 확진자 수 만 사용 - usecols=[3]
print(dataframe)
dataset = dataframe.values
# 가져온 데이터에는 설명(confirmed)과 순서에 대한 값이 포함되어 있는데 필요한 값만 가져오겠단 의미
dataset = dataset.astype('float32')
# 정규화 - 나눗셈사용 - 소수점 단위까지 필요해서 실수형으로 변경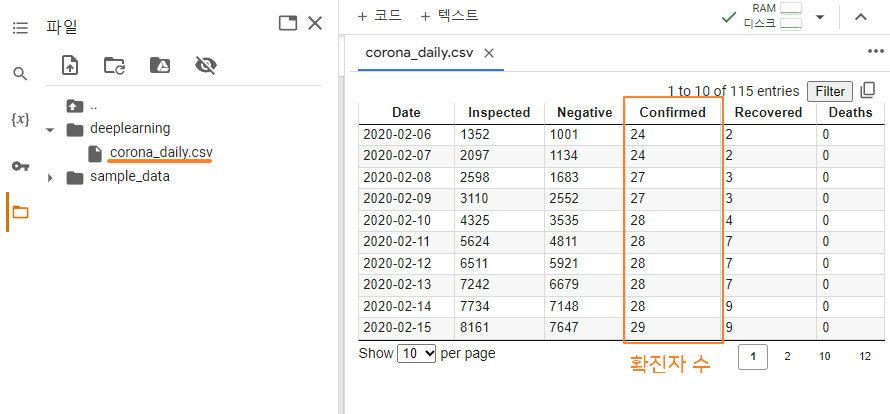
인공지능 모델 성능 높이려면 정규화가 필요 / 데이터를 0 ~ 1로 바꿔서 사용
scaler = MinMaxScaler(feature_range=(0, 1)) # 정규화 - 사이킷런 라이브러리 중 MinMaxScaler 함수 사용 / 정규화 범위를 0 ~ 1사이로 feature_range 지정 Dataset = scaler.fit_transform(dataset) # 실제 데이터(dataset)를 넣고 정규화 train_data, test_data = train_test_split(Dataset, test_size=0.2, shuffle=False) # 훈련 데이터와 검증 데이터 직접 분류 - test_size=0.2 : 훈련 데이터 0.8 / 검증 데이터 0.2로 나눠줌 # shuffle - 무작위로 가져올지 / 여기선 순서가 중요해서 무작위면 X print(len(train_data), len(test_data)) # 89 23
순환 신경망(RNN) 모델은 이전의 연속된 데이터를 사용하여 이후의 값을 예측함
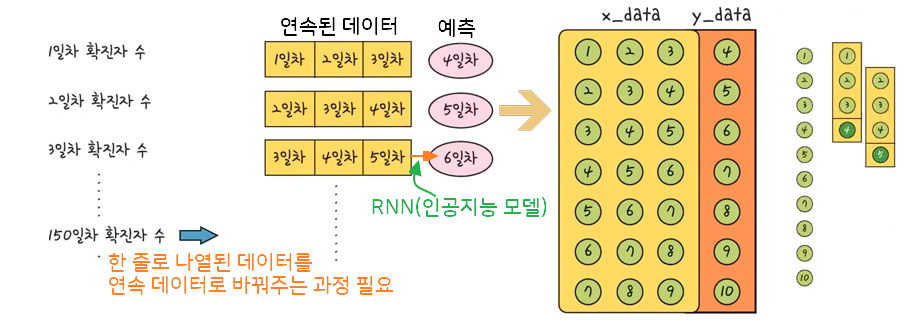
def create_dataset(dataset, look_back): # 원래 데이터(dataset) / 연속되는 데이터 개수(look_back)
x_data = []
y_data = []
for i in range(len(dataset) - look_back): # 전체 데이터 10개 라면 7번 반복(3일치 데이터)
data = dataset[i:(i+look_back) ,0] # ex> (dataset[0:3],0) : 0, 1, 2
x_data.append(data)
y_data.append(dataset[i + look_back, 0])
return np.array(x_data), np.array(y_data)look_back = 3 # 3일간 연속 데이터 x_train, y_train = create_dataset(train_data, look_back) # x_train - 3일치 연속 값 x_test, y_test = create_dataset(test_data, look_back) # y_train - 인공지능이 학습할 값 print(x_train.shape, y_train.shape) print(x_test.shape, y_test.shape) # (86, 3) (86,) # (20, 3) (20,)
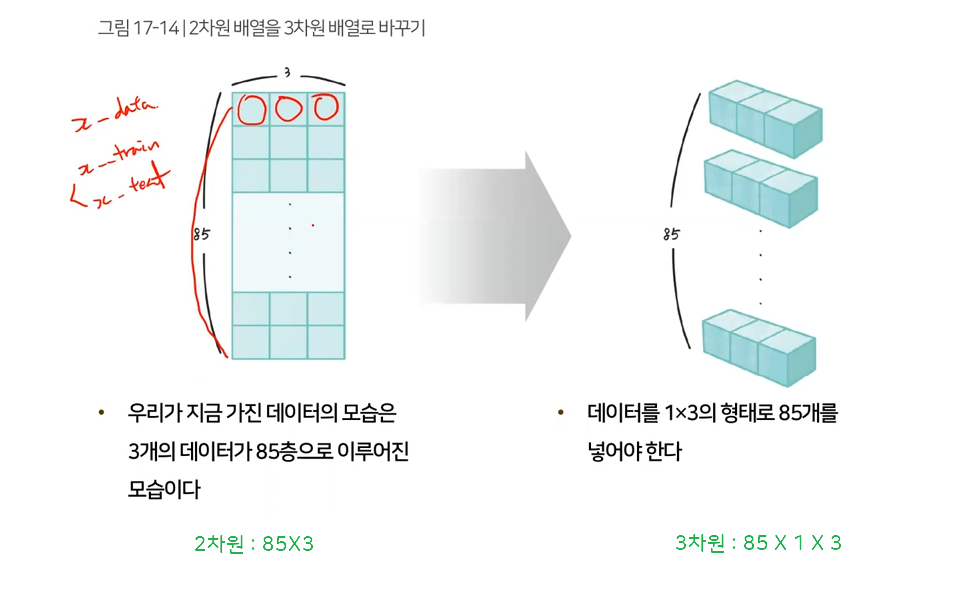
X_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1])) X_test = np.reshape(x_test, (x_test.shape[0], 1, x_test.shape[1])) print(X_train.shape) print(X_test.shape) # (86, 1, 3) (20, 1, 3)
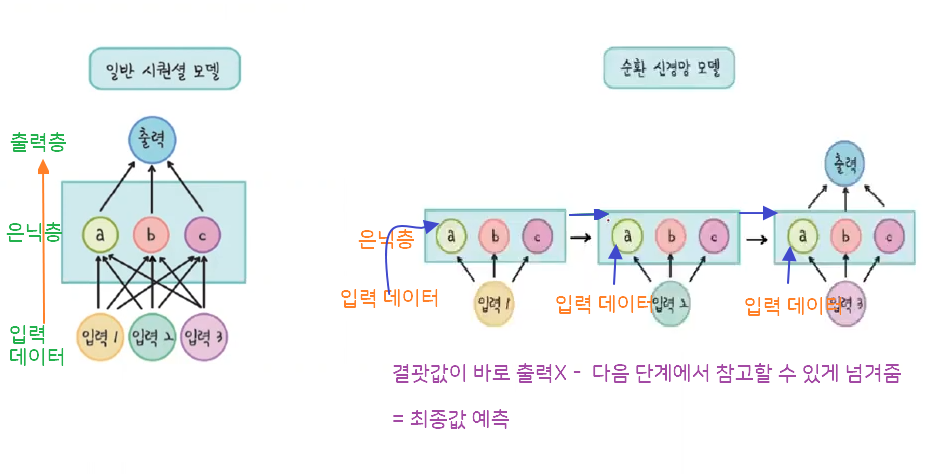
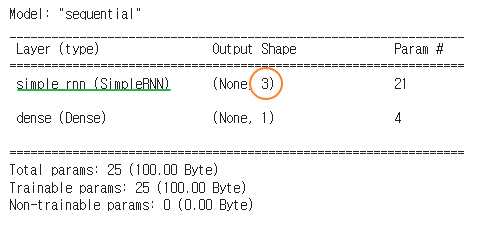
model = Sequential() # 순환 신경망 역시 선형이기에 모델은 시퀀셜모델로 설정 model.add(SimpleRNN(3, input_shape=(1, look_back))) # 뉴런 3개(변경 가능), 어떤 데이터 넣을지 결정 model.add(Dense(1, activation = 'linear')) # 여러 개 값이 아닌 1개 값으로 - 노드 1 구성 model.compile(loss='mse', optimizer='adam') # 오차=손실 함수는 mse(평균 제곱 오차) model.summary()
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1)

모델의 성능을 측정하려면 실제 데이터를 예측한 값과 실제 데이터의 값의 차이를 봐야 함
그러므로 정규화 거친 결과가 아닌 실제 확진자 수 데이터가 필요함
RNN 모델을 통해 나온 예측 값과 실제 값을 정규화 되기 전 값으로 변환 필요
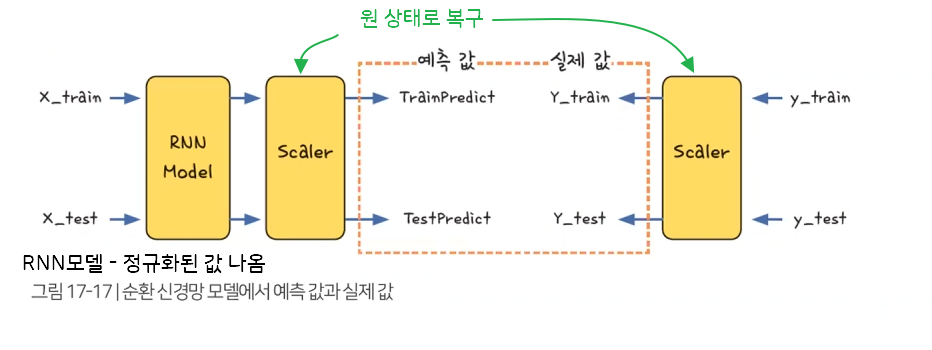
trainPredict = model.predict(X_train) # 모델에 데이터 넣어 결괏값 생성 함수 testPredict = model.predict(X_test) TrainPredict = scaler.inverse_transform(trainPredict) Y_train = scaler.inverse_transform([y_train]) # 실제 확진자 수 = 정답 TestPredict = scaler.inverse_transform(testPredict) Y_test = scaler.inverse_transform([y_test]) print(TrainPredict)
모델이 예측한 값과 실제 값에는 어느 정도 차이가 있는지 살펴보기
이때 사용하는 함수는 평균 제곱근 오차(Root Mean Squared Error)로 평균 제곱 오차를 제곱근한 값
trainScore = math.sqrt(mean_squared_error(Y_train[0], TrainPredict[:,0]))
# sqrt - 제곱근 / Y_train[0] - 실제 정답 값 전체 / TrainPredict - 예측 값 전체
# mean_squared_error 함수가 자동으로 오차의 값 제곱하여 각각의 값 더한 결과 반환
print('Train Score : %.2f RMSE' % (trainScore))
# %f(실수) %.2f(소수2자리까지) - %가 나오면 뒤에 값 넣겠다는 의미
testScore = math.sqrt(mean_squared_error(Y_test[0], TestPredict[:,0]))
print('Test Score : %.2f RMSE' % (testScore))
# Train Score : 131.66 RMSE
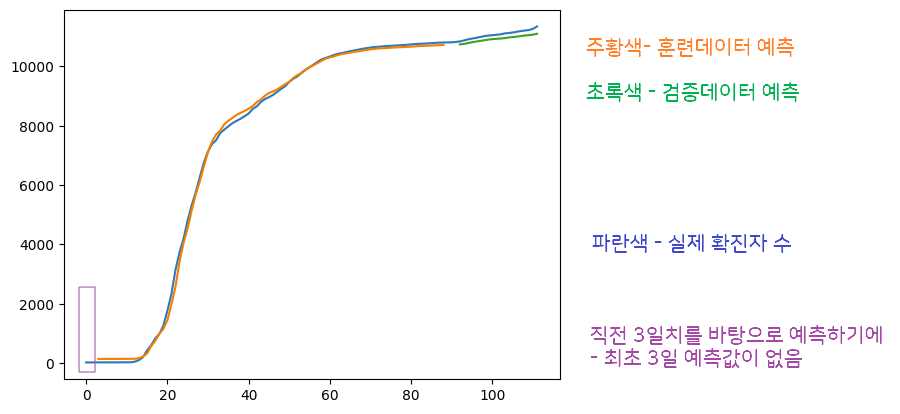
Test Score : 152.42 RMSE평균 제곱근 오차(RMSE)를 구해서 모델의 정확도를 살펴보았지만. 한 눈에 파악 힘듦 – 그래프로
trainPredictPlot = np.empty_like(dataset) # 전체 데이터(dataset)와 동일한 형태의 넘파일 배열 만들기 - 파란색. 초록색 빈 것 만들어 채워 넣기 trainPredictPlot[:, :] = np.nan # np.nan : 배열의 값 초기화 / : 은 모든 값 의미 - (처음):(마지막)에서 처음과 마지막 생략 = 전체 값 초기화 trainPredictPlot[look_back:len(TrainPredict) + look_back, :] = TrainPredict # 훈련 데이터를 예측한 결과 값 배열에 넣기 / (3일치까지 빼고 4일치부터) : 3칸 더해서 넣기 : (마지막) testPredictPlot = np.empty_like(dataset) # 검증 데이터 배열 만들기 testPredictPlot[:, :] = np.nan # 검증 데이터 없음으로 만들기 testPredictPlot[len(TrainPredict) + (look_back)*2: len(dataset), :] = TestPredict # 검증 데이터는 뒤에 다 넣기 - 훈련 데이터 뒤에 붙이기: 훈련 데이터 + 3칸 씩 2번 뛴 거 : 마지막 plt.plot(dataset) # 파란 그래프 그림 plt.plot(trainPredictPlot) plt.plot(testPredictPlot) # 훈련 데이터로 예측 값과 검증 값 각 넣기 plt.show() # 화면에 나타냄
[모두의 인공지능 with 파이썬] 첫째마당. 인공지능 개념 이해하기
[모두의 인공지능 with 파이썬] 둘째마당. 딥러닝 이해하기
[모두의 인공지능 with 파이썬] 셋째마당 인공지능 개발을 위한 파이썬 첫걸음
[모두의 인공지능 with 파이썬] 넷째마당 딥러닝 프로그래밍 시작하기 1
[모두의 인공지능 with 파이썬] 넷째마당 딥러닝 프로그래밍 시작하기 2 – 숫자 인식 인공지능 만들기